.thumb.png.c9faf450e4d2b690a819048b18173f61.png)

About This File
This is a reboot of the Movie Scraper Plugin by @Slipstream.
The intent of this plugin is to scrape metadata and media for movies you’ve imported into LaunchBox.
Q&A:
Why use LaunchBox as your digital movie library?
Because you can.
What metadata is imported?
- Title
- Notes (Movie Plot)
- Release Date
- Publisher (Production Studio i.e. “Marvel Studios”)
- Genre(s)
- Series (Collection i.e. “The Avengers Collection”)
- Video Url (YouTube movie trailer)
What media is imported?
- Box – Front
- Banner
- Clear Logo
- Disc
- Fanart – Background
- Arcade – Marquee
Can it import media I already have?
Yes. When importing media, the plugin will 1st look in the same folder the movie file is located.
Do I need to have my own personal API keys for both TMDB and FanArt.TV?
Yes.
However, when running Setup the first time, “temporary” API keys are automatically inserted. For now, they work. But for best, continued results, obtain and enter in your own keys. (See below)
Are both API keys required to scape?
Yes. If either of the keys are missing or invalid, the plugin will exit.
Do the Movie Titles [in LaunchBox] need to be named a certain way before scraping?
Yes. The Titles should be the name of the movie without any extras.
- The Avengers will work.
- The Avengers (2012) will work. (new v1.3.0)
- The Avengers 2012 will not work.*
- The.Avengers.2012.1080p.BluRay.x264.DTS-FGT will not work.*
*No. If you have a valid Information (NFO) file in the same folder as the movie, the plugin will parse the file to get the proper Title and movie ID#.
- The Avengers 2012 will work.
- The.Avengers.2012.1080p.BluRay.x264.DTS-FGT will also work.
Can I scrape more than one movie at a time?
Yes. Select multiple (or all) movies in the Platform, right-click and select Scrape Movie.
- You may want to test with just one movie or only a couple at first.
Can I scrape metadata in a language other than English?
Yes. See Setup: below. (new v1.3.0)
Installation:
- Download the zip file
-
Unblock it by right-clicking the file, select Properties, check “Unblock” and click OK.
- (Alternately, just use 7Zip to open the downloaded file)
-
Copy the folder inside the zip into ../LaunchBox/Plugins/
- i.e. D:\LaunchBox\Plugins\MovieScraper2023\MovieScraper.dll
Setup:
- Start LaunchBox
-
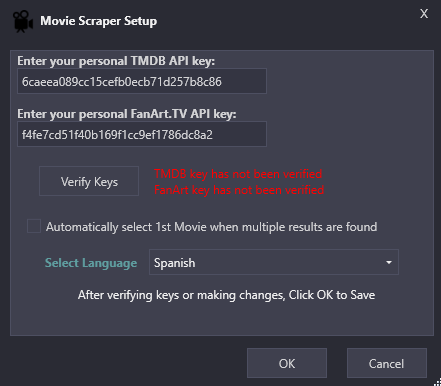
Click Tools and select “Movie Scraper Setup”
- Enter in your API keys
- Click Verify Keys to confirm they are working
- (Optional) Check “Automatically select 1st Movie when multiple results are found”
- (Optional) Select a language to use when downloading metadata. (Default: English) (new v1.3.0)
- Click Save
Use:
- Select one or movies you have imported into LaunchBox, then right-click on one of them.
-
Select Scrape Movie
- A “Please Stand By” window will appear indicating scraping is in progress.
-
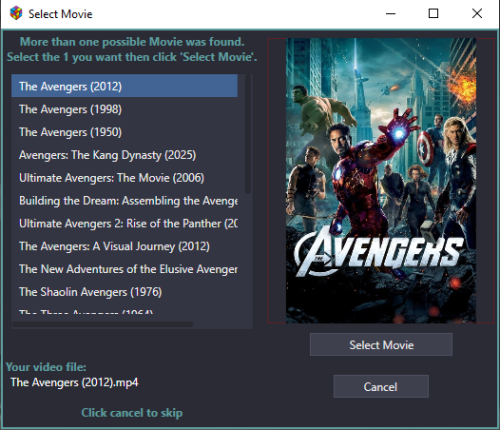
If a movie has more than one ‘close match’, a window will appear where you can select the correct movie.
- Unless during Setup, you checked “Automatically select 1st Movie when multiple results are found”.
- Scraping is complete when “Please Stand By” disappears.
- When completed, press F5 to refresh the Box-Front images for the selected movie(s). Click on a different movie and then back on one just scraped to refresh the images in the right side-bar.
Getting your personal API keys: (both are free to get)
TMDB
A TMDB user account is required to get an API key. Once created, log in and go to Profile - Overview - Edit Profile. Go down to API to get your “api_key (v3 auth)”. http://www.themoviedb.org
FanArt.TV
Register an account at https://fanart.tv/. Once registered, go to https://fanart.tv/get-an-api-key/ to find your personal key
The process when scraping:
-
Get the API keys from APIfile.xml and verify the API keys are valid
- If either API key returns “Unauthorized”, the plugin will exit
-
Check if the movie has an NFO file (in the same folder as the video file). If so…
- Get/store the movies ID#. (Can be either TMDB or IMDB)
- Set the ‘games’ Title
-
Check for existing image files in the same folder as the video file. If any exist, copy them into LB
- Image files need to have the same name as the video file, plus -imageType.png (or .jpg depending on the image type)
-
Search TMDB using ‘Title’. (If an NFO file exists, search by the movie ID# from step 2 above)
-
If no matches, “The movie could not be found.” [popup message] will appear.
- When scraping in bulk, a popup will appear at the end of all scraping instead, listing the movies not found
- If there are multiple matches, a window will appear to have you select the correct movie. (Unless you chose to “Automatically select 1st Movie” during Setup)
-
If there’s only 1 match (or when a movie was manually selected), set the movies:
- Title, Notes, Release Date, Publisher, Genre(s), Series and Video Url (link to movie trailer)
-
If no matches, “The movie could not be found.” [popup message] will appear.
- Download images from TMDB and FanArt.TV. Download images only if the image type doesn’t already exist (i.e. local images weren’t found)
Order of precedence for importing images:
Local images:
Box-Front
Banner
Clear Logo
Disc
Fanart-Background
Arcade-Marquee
TMDB:
Box-Front
Fanart-Background
FanArt.TV:
Box-Front
Banner
Clear Logo
Disc
Fanart-Background
Arcade-Marquee
When selecting a language other than English (new option v1.3.0) to download metadata, Box-Front and Background images are the only ones that will appear in that language (if available). FanArt.TV doesn't appear to support other languages.
Big thanks to @Slipstream for the original code and @jayjay for his update. Thanks to @universeofgamer for the suggestion to add the option to scrape metadata in other languages.
As always, all comments and suggestions are welcomed.
What's New in Version 1.4.0 See changelog
Released
Fixed: Error appears when selecting extraordinarily high grossing movies (i.e. Avatar at $2,923,706,026)
Fixed: Movie-specific Background images wouldn't download if the Platform had an existing Fanart image.
Changed: Downloaded Background image size from a width of 500 to the largest size available from TMDB.



Recommended Comments
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.